Hidden Markov Model (HMM)
A HMM is a simple deterministic model where the transition functions and the generating functions are independent. In other words, the model first generate an observation and then move to the next state according to two independent probability distributions. More information here.
Example
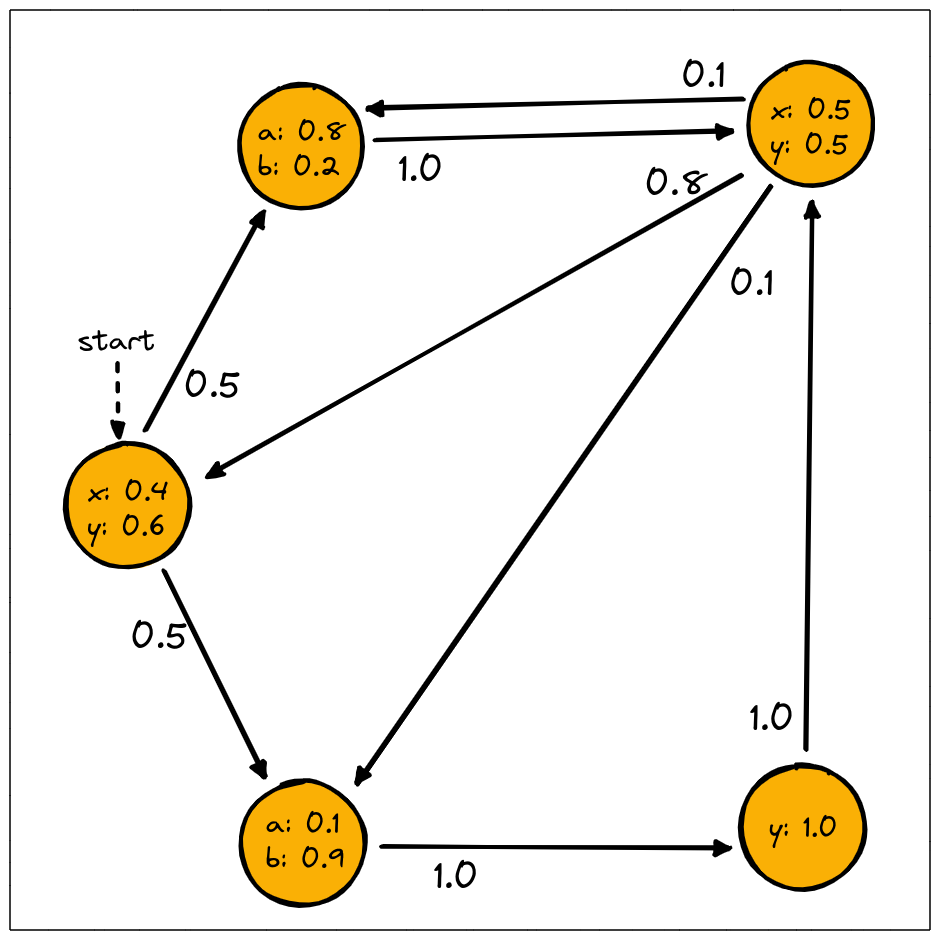
Creation
>>> import jajapy as ja
>>> transitions = [(0,1,0.5),(0,2,0.5),(1,3,1.0),(2,4,1.0),
>>> (3,0,0.8),(3,1,0.1),(3,2,0.1),(4,3,1.0)]
>>> emission = [(0,"x",0.4),(0,"y",0.6),(1,"a",0.8),(1,"b",0.2),
>>> (2,"a",0.1),(2,"b",0.9),(3,"x",0.5),(3,"y",0.5),(4,"y",1.0)]
>>> original_model = ja.createHMM(transitions,emission,initial_state=0,name="My HMM")
We can also generate a random HMM
>>> random_model = ja.HMM_random(number_states=5,
random_initial_state=False,
alphabet=['x','y','a','b'])
Exploration
>>> model.a(0,1) #probability of going from s0 to s1
0.5
>>> model.a(1,3) #probability of going from s1 to s3
1.0
>>> model.b(0,'x') #probability of seeing 'x' while in s0
0.4
>>> model.tau(0,1,'x') #probability of going from s0 to s1 seeing 'x'
0.2
>>> model.getAlphabet() #all possible observations
['x','y','a','b']
>>> model.getAlphabet(0) #all possible observations in s0
['x','y']
Running
>>> model.run(5) # Generate a run of length 5, i.e. returns a list of 5 observations
['y', 'a', 'y', 'a', 'y']
>>> s = model.generateSet(10,5) # returns a Set containing 10 traces of length 5
>>> s.sequences
[['x', 'a', 'x', 'y', 'a'], ['x', 'b', 'y', 'x', 'a'],
['y', 'b', 'y', 'a', 'x'], ['y', 'b', 'x', 'y', 'b'],
['x', 'b', 'x', 'y', 'a'], ['y', 'b', 'y', 'y', 'x'],
['y', 'b', 'y', 'y', 'y'], ['y', 'a', 'y', 'a', 'y'],
['y', 'a', 'x', 'a', 'y']]
>>> s.times
[1, 1, 1, 1, 1, 1, 2, 1, 1]
>>> # all the traces appear once in the set, except the 7th which appears twice
Analysis
>>> model.logLikelihood(s) # loglikelihood of this set of traces under this model
-4.442498878506513
Saving/Loading
>>> model.save("my_hmm.txt")
>>> model2 = ja.loadHMM("my_hmm.txt")
Model
- class jajapy.HMM(matrix, output, alphabet, initial_state, name='unknown_HMM')
Creates an HMM.
Parameters
- matrixndarray
Represents the transition matrix. matrix[s1][s2] is the probability of moving from s1 to s2.
- outputndarray or list
Represents the output matrix. output[s1][obs] is the probability of seeing alphabet[obs] in state s1.
- alphabet: list
The list of all possible alphabet, such that: alphabet.index(“obs”) is the ID of obs.
- initial_stateint or list of float
Determine which state is the initial one (then it’s the id of the state), or what are the probability to start in each state (then it’s a list of probabilities).
- namestr, optional
Name of the model. Default is “unknow_MC”
- a(s1: int, s2: int) → float
Returns the probability of moving from state s1 to state s2. If s1 or s2 is not a valid state ID it returns 0.
Parameters
- s1int
ID of the source state.
- s2int
ID of the destination state.
Returns
- float
Probability of moving from state s1 to state s2.
Examples
>>> model.a(0,1) 0.5 >>> model.a(0,0) 0.0
- b(s: int, l: str) → float
Returns the probability of generating l in state s. If s is not a valid state ID it returns 0.
Parameters
- sint
ID of the source state.
- lstr
observation.
Returns
- float
probability of generating l in state s.
Examples
>>> model.b(0,'x') 0.4 >>> model.b(0,'foo') 0.0
- generateSet(set_size: int, param, distribution=None, min_size=None, timed: bool = False) → Set
Generates a set (training set / test set) containing
set_sizetraces.Parameters
- set_size: int
number of traces in the output set.
- param: a list, an int or a float.
the parameter(s) for the distribution. See “distribution”.
- distribution: str, optional
If
distribution=='geo'then the sequence length will be distributed by a geometric law such that the expected length ismin_size+(1/param). If distribution==None param can be an int, in this case all the seq will have the same length (param), orparamcan be a list of int. Default is None.- min_size: int, optional
see “distribution”. Default is None.
- timed: bool, optional
Only for timed model. Generate timed or non-timed traces. Default is False.
Returns
- output: Set
a set (training set / test set).
Examples
>>> set1 = model.generateSet(100,10) >>> # set1 contains 100 traces of length 10 >>> set2 = model.generate(100, 1/4, "geo", min_size=6) >>> # set2 contains 100 traces. The length of the traces is distributed following >>> # a geometric distribution with parameter 1/4. All the traces contains at >>> # least 6 observations, hence the average length of a trace is 6+(1/4)**(-1) = 10.
- getAlphabet(state: int = -1) → list
If state is set, returns the list of all the observations we could see in state. Otherwise it returns the alphabet of the model.
Parameters
- stateint, optional
a state ID
Returns
- list of str
list of observations
- logLikelihood(sequences: Set) → float
Compute the average loglikelihood of a set.
Parameters
- sequences: Set
A set.
Returns
- output: float
loglikelihood of
sequencesunder this model.
Examples
>>> model.logLikelihood(set1) -4.442498878506513
- next(state: int) → list
Returns a state-observation pair according to the distributions described by self.matrix[s] and self.output[s].
Parameters
- stateint
ID of the source state.
Returns
- output[int, list of floats]
A state-observation pair.
- next_obs(state: int) → str
Generates one observation according to the distribution described by self.output_matrix.
Returns
- str
An observation.
- next_state(state: int) → int
Returns one state ID at random according to the distribution described by the self.matrix.
Parameters
- stateint
ID of the source state.
Returns
- int
A state ID.
- pi(s: int) → float
Return the probability of starting in state
s.Parameters
- s: int
state ID.
Returns
- outputfloat
the probability of starting in state s.
- run(number_steps: int, current: int = -1) → list
Simulates a run of length
number_stepsof the model and return the sequence of observations generated.Parameters
- number_steps: int
length of the simulation.
- currentint, optional.
If current it set, it starts from the state current. Otherwise it starts from an initial state.
Returns
- output: list of str
trace generated by the run.
- save(file_path: str)
Save the model into a text file.
Parameters
- file_pathstr
path of the output file.
Examples
>>> model.save("my_model.txt")
- tau(s1: int, s2: int, obs: str) → float
Return the probability of generating from state s1 observation obs and moving to state s2. If s1 or s2 is not a valid state ID it returns 0.
Parameters
- s1int
ID of the source state.
- s2int
ID of the destination state.
- obsstr
An observation.
Returns
- float
The probability of generating from state s1 observation obs and moving to state s.
Examples
>>> model.tau(0,1,'x') 0.2
Other Functions
- jajapy.createHMM(transitions: list, emission: list, initial_state, name: str = 'unknown_HMM') → HMM
An user-friendly way to create a HMM.
Parameters
- transitions[ list of tuples (int, int, float)]
Each tuple represents a transition as follow: (source state ID, destination state ID, probability).
- emission[ list of tuples (int, str, float)]
Each tuple represents an emission probability as follow: (source state ID, emitted label, probability).
- initial_stateint or list of float
Determine which state is the initial one (then it’s the id of the state), or what are the probability to start in each state (then it’s a list of probabilities).
- namestr, optional
Name of the model. Default is “unknow_HMM”
Returns
- HMM
the HMM describes by transitions, emission, and initial_state.
Examples
>>> model = createHMM([(0,1,1.0),(1,0,0.6),(1,1,0.4)],[(0,'a',0.8),(0,'b',0.2),(1,'b',1.0)],0,"My_HMM") >>> print(model) Name: My_HMM Initial state: s0 ----STATE s0---- s0 -> s1 : 1.0 ************ s0 => a : 0.8 s0 => b : 0.2 ----STATE s1---- s1 -> s0 : 0.6 s1 -> s1 : 0.4 ************ s1 => b : 1.0
- jajapy.loadHMM(file_path: str) → HMM
Load an HMM saved into a text file.
Parameters
- file_pathstr
Location of the text file.
Returns
- outputHMM
The HMM saved in file_path.
- jajapy.HMM_random(nb_states: int, alphabet: list, random_initial_state: bool = False, sseed: Optional[int] = None) → HMM
Generates a random HMM.
Parameters
- nb_statesint
Number of states.
- alphabetlist of str
List of observations.
- random_initial_state: bool, optional
If set to True we will start in each state with a random probability, otherwise we will always start in state 0. Default is False.
- sseedint, optional
the seed value.
Returns
- HMM
A pseudo-randomly generated HMM.
Examples
>>> m = ja.HMM_random(4,['a','b','x','y'])