3. Learning an MDP from a prism file
python file
prism model for the grid
For this example, we will learn the grid world model depicted below.
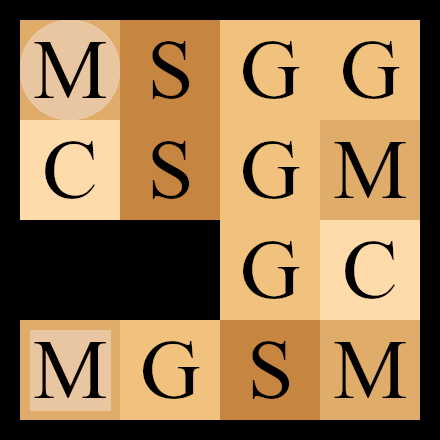
We start in the top-left cell and our destination is the bottom-right one. We can move in any of the four directions North, South, East and West. We may make errors in movement, e.g. move south west instead of south with an error probability depending on the target terrain.
This model is form this paper.
Loading the original model from a Prism file
The original model is described in a Prism file. Let’s first load it.
>>> import jajapy as ja
>>> actions = list('nsew')
>>> labels = list("SMGCW")+["GOAL"]
>>> original_model = ja.loadPrism('materials/grid_4x4.sm')
>>> original_model.actions = actions # otherwise the actions are a0, a1, etc...
The last line matters: in fact, the actions name are lost in the process, and replaced by a0, a1, a2, a3. This problem will be (hopefully) solved in the next releases.
You may notice, if you try this on your machine, that the command loadPrism clears the terminal.
The reason is that loading a Prism file causes many warnings/errors prints even if, at the end,
everything went well (yes, I know it is hard to believe, but trust me). Hence, to avoid panic,
the command clear the terminal and the user is serene.
Generating the training set
We can now generate the training. However, since MDPs are non-deterministic models, we need a scheduler to resolve the non-deterministic choices. We will use here an uniform scheduler.
>>> # We generate 1000 sequences of 10 observations for each set,
>>> # using an uniform scheduler to resolve the non-deterministic choices.
>>> training_set = original_model.generateSet(1000,10,scheduler=ja.UniformScheduler(actions))
Generating the initial hypothesis
The system under learning contains 26 states, and only 6 labels. Hence, if we let Jajapy generate a random MDP with 26 states for the training set, the first 6 states will be labeled with S, C, M, G, W and GOAL, and the 20 remaining will be labeled randomly. Hence, we could possibly have 21 states labeled with GOAL and only one with W, which is far away from what we have in the system under learning.
Here, we will first randomly generate our initial hypothesis, and then modify its labelling to have an initial hypothesis closer to the system under learning.
One to overcome this problem is presented in 5. Learning CTMCs.
>>> initial_hypothesis = ja.MDP_random(nb_states=26,labelling=labels,actions=actions,random_initial_state=False)
WARNING: the size of the labelling is lower than the number of states. The labels for the last states will be chosen randomly.
>>> initial_hypothesis.labelling = original_model.labelling
Note
Before doing that, we must be sure that the init label is at the same index in both initial_hypothesis.labelling and
original_model.labelling, and that they both have the same length. Here, we now that our initial hypothesis has as many
state as the original model, thus the two lists have the same length. And we know that the init label is the last one in
these two lists.
Learning
Now, we can learn the model as follows:
>>> output_model = ja.BW().fit(training_set,initial_model=initial_hypothesis)
|████████████████████████████████████████| (!) 34 in 50.4s (0.67/s)
---------------------------------------------
Learning finished
Iterations: 34
Running time: 50.440811
---------------------------------------------
The learning took some time, as we can observe. One way to speed up it is to bound the number of BW iterations using the
max_it parameter of the fit method. But this techniques reduces the quality of the ouptput model.
By default, the number of iterations is not bounded.
Model checking and evaluation
We can now model check the output model and compare the results with the original one.
>>> import stormpy
>>> formulas = ["Pmax=? [ F<=5 \"GOAL\" ]","Pmax=? [ !(\"C\"|\"W\") U<=8\"GOAL\" ]", "Pmax=? [ F<=12 \"GOAL\" ]"]
>>> original_model = ja.jajapyModeltoStormpy(original_model)
>>> for formula in formulas:
>>> properties = stormpy.parse_properties(formula)
>>> result_original = stormpy.check_model_sparse(original_model, properties[0])
>>> result_original = result_original.at(original_model.initial_states[0])
>>> result_output = stormpy.check_model_sparse(output_model, properties[0])
>>> result_output = result_output.at(output_model.initial_states[0])
>>> print(formula,'in the original model:',str(result_original))
>>> print(formula,'in the output model:',str(result_output))
>>> print()
Pmax=? [ F<=7 "GOAL" ] in the original model: 0.9559679999999999
Pmax=? [ F<=7 "GOAL" ] in the output model: 0.9536424030117392
Pmax=? [ !("C"|"W") U<=7 "GOAL" ] in the original model: 0.6417319531249999
Pmax=? [ !("C"|"W") U<=7 "GOAL" ] in the output model: 0.6753756876616249
Pmax=? [ F<=12 "GOAL" ] in the original model: 0.9995491123199998
Pmax=? [ F<=12 "GOAL" ] in the output model: 0.9995784084581394