5. Learning CTMCs
In this example, we will:
Create a CTMC H from scratch,
Use it to generate a training set,
Use the Baum-Welch algorithm to learn, from the training set, H,
Compare H with the model generated at the previous step.
Creating a CTMC
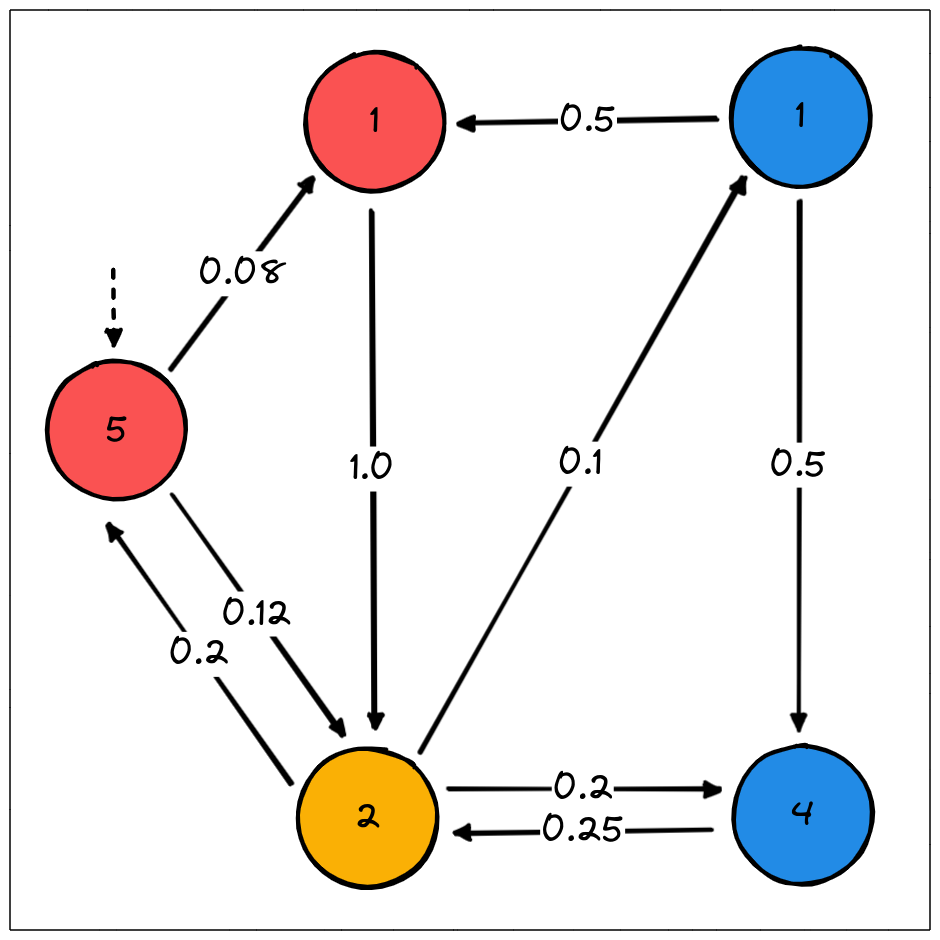
In the model above, the colour of each state indicates its label, the numbers on the states corresponds to the expected dwell times (i.e. the inverse of the sum of the leaving rates), and the numbers on the transitions shows the rates.
We can create the model depicted above like this:
import jajapy as ja
>>> labelling = ['red','red','yellow','blue','blue']
>>> # We move from state 0 to state 1 with a rate of 0.08, and so on...
>>> transitions = [(0,1,0.08),(0,2,0.12),(1,1,0.3),(1,2,0.7),
(2,0,0.2),(2,3,0.1),(2,4,0.2),(3,3,0.8),
(3,1,0.1),(3,4,0.1),(4,2,0.25)]
>>> original_model = ja.createCTMC(transitions,labelling,initial_state=0,name="My_CTMC")
Generating a training set
Now we can generate a training set. This training set contains 1,000 traces of length 10, with the dwell times.
>>> # We generate 1000 sequences of 10 observations for each set,
>>> # including the dwell times.
>>> training_set = original_model.generateSet(1000,10,timed=True)
>>> test_set = original_model.generateSet(1000,10,timed=True)
Generating the initial hypothesis
The system under learning contains 5 states, and only 3 different labels. Hence, if we let Jajapy generate a random CTMC with 5 states for the training set, the first 3 states will be labeled with blue, red and yellow, and the 2 remaining will be labeled randomly. Thus, we could possibly have 3 states labeled with yellow and only one with blue, which is far away from what we have in the system under learning.
To overcome this problem we will generate 10 different random CTMCs and pick the one which maximizes the loglikelihood of the test set.
In the following, we assume that we know the 3 possible labels (otherwise we can simply look into the training set),
and that we have some knowledge of the minimum and maximum exit rate in the states.
Although, it is better to set random_initial_state to True, otherwise, if the randomly choosen intial state
is not labeled as the one in the system under learning, our random model will not be able to generate any of the trace
in the training/test set, and it will be impossible for the BW algorithm to learn anything with this model as initial
hypothesis.
>>> nb_trials = 10
>>> best_model = None
>>> quality_best = -1024
>>> for n in range(1,nb_trials+1):
>>> current_model = ja.CTMC_random(nb_states=5,
>>> labelling=['red','yellow','blue'],
>>> self_loop=False,
>>> random_initial_state=True,
>>> min_exit_rate_time=0.5,
>>> max_exit_rate_time=6.0)
>>> current_quality = current_model.logLikelihood(test_set)
>>> if quality_best < current_quality: #we keep the best model only
>>> quality_best = current_quality
>>> best_model = current_model
WARNING: the size of the labelling is lower than the number of states. The labels for the last states will be chosen randomly.
[...]
WARNING: the size of the labelling is lower than the number of states. The labels for the last states will be chosen randomly.
>>> print(best_model.labelling)
['red', 'yellow', 'blue', 'blue', 'blue', 'init']
The best model labelling is very close to the original model one. In fact, we can even argue that we can build a model equivalent to the original one by merging properly the two red states.
Learning a CTMC using BW
Let now use our training set and initial hypothesis to learn original_model :
>>> output_model = ja.BW().fit(training_set,initial_model=best_model)
|████████████████████████████████████████| (!) 73 in 16.5s (4.43/s)
---------------------------------------------
Learning finished
Iterations: 73
Running time: 16.513442
---------------------------------------------
Evaluating the BW output model using model checking
Eventually, we compare the output model with the original one. We can do so by comparing the value of some properties under this two models as follows:
>>> # We convert the original model to a Stormpy one,
>>> # to compare the model checking results.
>>> original_model = ja.jajapyModeltoStormpy(original_model)
>>> formulas = ["T=? [ F \"blue\" ]", "P=? [ F>5 \"blue\" ]"]
>>> for formula in formulas:
>>> properties = stormpy.parse_properties(formula)
>>> result_original = stormpy.check_model_sparse(original_model, properties[0])
>>> result_original = result_original.at(original_model.initial_states[0])
>>> result_output = stormpy.check_model_sparse(output_model, properties[0])
>>> result_output = result_output.at(output_model.initial_states[0])
>>> print(formula,'in the original model:',str(result_original))
>>> print(formula,'in the output model active:',str(result_output))
>>> print()
T=? [ F "blue" ] in the original model: 1.0
T=? [ F "blue" ] in the output model active: 1.1338952888803142
P=? [ F>5 "blue" ] in the original model: 11.604726386373011
P=? [ F>5 "blue" ] in the output model active: 13.77803014164066