9. Learning an MC with Alergia
This time we will try to learn the Reber grammar. using Alergia.
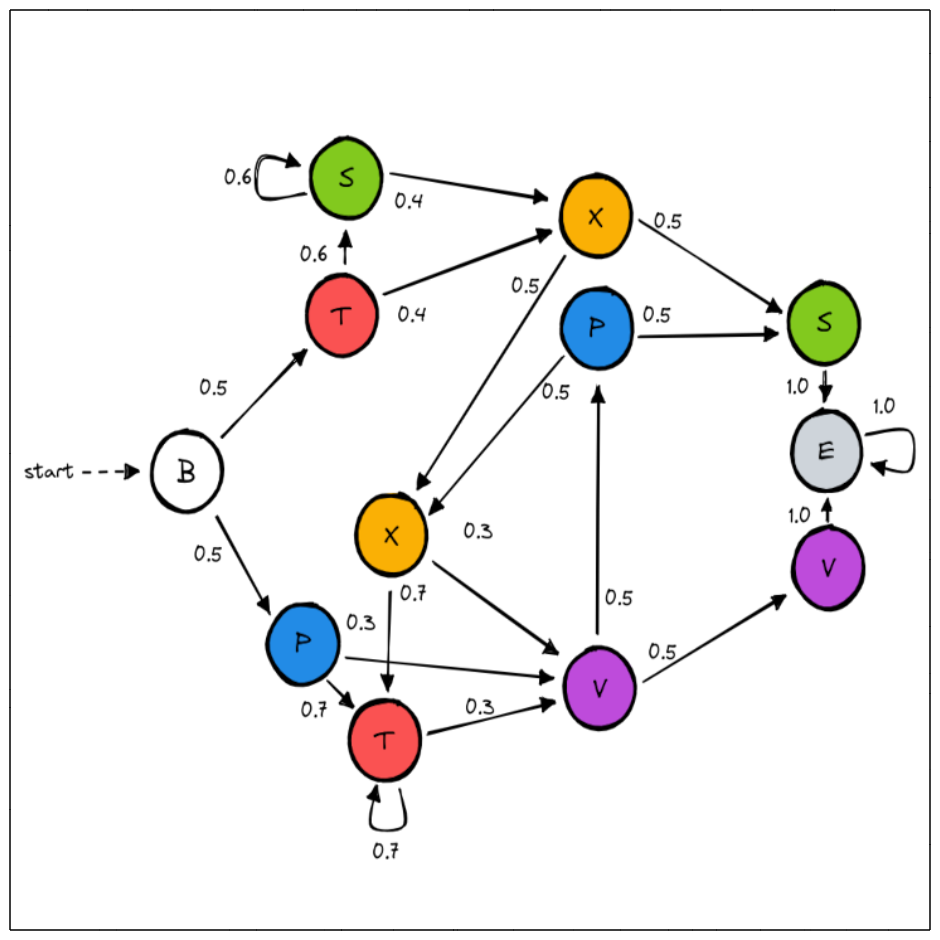
Creating the original MC and generating the training set
This step is similar to the first steps in 2. Learning an MC with random restart.
>>> import jajapy as ja
>>> # State 0 is labelled with B, state 1 with T, etc...
>>> labelling = list("BTSXSPTXPVVE")
>>> initial_state = 0
>>> name = "MC_REBER"
>>> # From state 0 we move to state 1 with probability 0.5
>>> # and to state 5 with probability 0.5, and so on...
>>> transitions = [(0,1,0.5),(0,5,0.5),(1,2,0.6),(1,3,0.4),(2,2,0.6),(2,3,0.4),
>>> (3,7,0.5),(3,4,0.5),(4,11,1.0),(5,6,0.7),(5,9,0.3),
>>> (6,6,0.7),(6,9,0.3),(7,6,0.7),(7,9,0.3),(8,7,0.5),(8,4,0.5),
>>> (9,8,0.5),(9,10,0.5),(10,11,1.0),(11,11,1.0)]
>>> original_model = ja.createMC(transitions,labelling,initial_state,name)
>>>
>>> # We generate 1000 sequences of 10 observations for each set
>>> training_set = original_model.generateSet(10000,10)
>>> test_set = original_model.generateSet(10000,10)
Learning the MC using Alergia
We can now learn the model.
>>> alergia_model = ja.Alergia().fit(training_set,alpha=0.1,stormpy_output=False)
We set stormpy_output to False since we want to compute some traces loglikelihood
afterward.
Output model evaluation
First, we notice that the output model is much bigger than the original one.
With a smaller alpha parameter we would have gotten a smaller output model.
>>> print(original.nb_states)
13
>>> print(alergia_model.nb_states)
68
Let’s evaluate our model under the test set:
>>> print('Loglikelihood for the original model :',original_model.logLikelihood(test_set))
Loglikelihood for the original model : -4.088923415999431
>>> print('Loglikelihood for Alergia output model:',alergia_model.logLikelihood(test_set))
Loglikelihood for Alergia output model: -4.088448560584602
And now under some properties. But first, we need to translate our Jajapy models to Stormpy sparse models.
>>> import stormpy
>>> alergia_model = alergia_model.toStormpy()
>>> original_model = original_model.toStormpy()
>>> formulas = ['P=? [ G !"P"]','P=? [ G !"X"]','P=? [ F<=5 "P"]']
>>> for formula in formulas:
>>> properties = stormpy.parse_properties(formula)
>>> result_original = stormpy.check_model_sparse(original_model,properties[0])
>>> result_alergia = stormpy.check_model_sparse(alergia_model,properties[0])
>>> print(formula+':')
>>> print("In the original model:",result_original.at(original_model.initial_states[0]))
>>> print("In the Alergia output model:",result_alergia.at(alergia_model.initial_states[0]))
P=? [ G !"P"]:
In the original model: 0.375
In the Alergia output model: 0.41302843135851
P=? [ G !"X"]:
In the original model: 0.375
In the Alergia output model: 0.39901057992766054
P=? [ F<=5 "P"]:
In the original model: 0.5
In the Alergia output model: 0.5026